



Many of we mainframe pundits have written about the robustness, power, perseverance, capacity and more importantly, the cost-effectiveness of the mainframe (Allingham, Sun, Peleg), including myself. But what about showing the superiority of the mainframe using real numbers, comparing it to other platforms? That requires a lot more work. Schroder and Olders shows us some real-world numbers, but how about showing the ugly details? That’s even more work, and fortunately, a couple of people have done that as well.
Michael Benson’s Enterprise Executive article in 2016 did that – since then, distributed servers have come a long way (AWS, Google and a host of other cloud service providers), but so has the mainframe. In 2015, the top-of-the-line mainframe was the z13, an outstanding business machine; today the z15 outperforms it considerably on many levels –speed, transaction throughput, security, flexibility, and more. A main argument then, as now, is cost; and that’s a losing argument right from the get-go.
Comparing Platform Costs
“Other platforms are cheaper…” This is the basic claim for most people interested in dumping mainframe systems in favor of commodity servers. Let’s face it, Google, Amazon and Microsoft don’t use mainframe systems at their back end, so why should anyone? That’s a great point, but let’s look at the premise first – are server farms less costly than the mainframe? Recently, Michael Benson did a study for Enterprise Executive magazine in an article called CIOs: Are You Really Paying Less by Using x86 Platforms? In it, he configured two similar performing platforms – one mainframe-based, using an IBM z13 mainframe system, and the other, a bank of HP servers. Table 1 shows the system specifications.
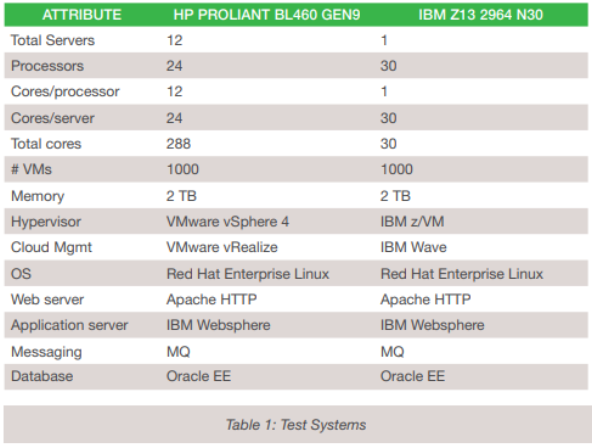
He explains that running Linux on the mainframe is no different than running it on x86 servers. The only real difference is the cost, and the belief is that x86 platforms do it for less. But do they? The hardware costs for these configurations run in at $2,299,451.00 for the server farm solution, and $2,793,371.00 for the mainframe solution. However, due to licensing costs, the software cost for the server farms comes in at $1,807,406.00, with the mainframe running at only $416,883.00.
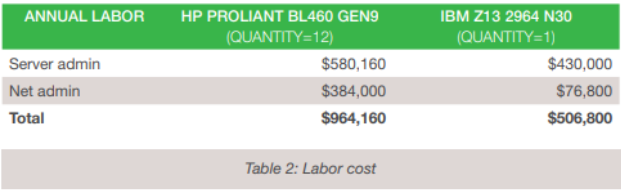
So yes, the hardware is cheaper, but there is not quite as much difference as you might expect. The real surprise is in the difference in software cost. When you also consider maintenance costs, the pattern is maintained. Maintenance costs for the server farm would come in at $390,327.00, with the mainframe at $269,767.00. Labor costs are also part of the picture.
At the end of the day, what really matters is the ongoing operational costs of the two platform solutions. Table 3 shows a considerable gap in favor of mainframe computing.
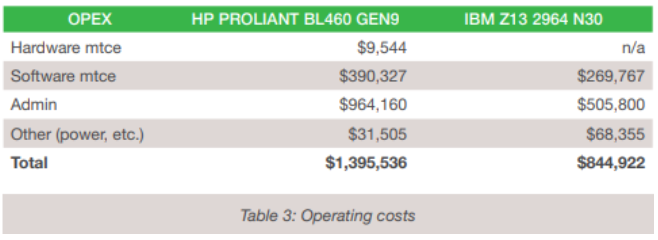
Over a five year period, operating costs compound, and the picture looks much worse for the server farm, $9,052,749.00 vs $6,979,693.00 in for the mainframe setup. The shocking conclusion therefore, is that it is cheaper to run the mainframe system than it is to run the server farm.
When doing cost comparisons, it is good practice to look at all contributing costs, and to look at long term cost of ownership. This comparison would have looked a lot different if we stuck to just the hardware acquisition cost, or even if we hid the personnel costs in a general employee pool rather than in the TCO calculations.
Technology Economics
Cost is one thing – often a very misunderstood thing, as Michael Benson pointed out. But acquisition and ongoing cost represent only one dimension in a complicated cost-comparison between platforms. What about environments that run a mix of mainframe and distributed systems? And what about comparing not just cost between platforms, but real costs in specific industries? Well, that’s where Dr. Howard A. Rubin of Rubin Worldwide, a technology economics research firm, comes in.
In his paper, The Surprising Technology Economics of Mainframe vs. Distributed Servers, Dr. Rubin explains that understanding computing platforms and their economic relevance in the context of their contributions to business performance is critical. This context provides a transparency that goes far beyond the basic economics of the costs of hardware and software acquisition or a TCO calculation. This is especially important when we consider that technology costs are a rising part of ongoing business operations expense.
IT costs vs business revenue and cost
Technology costs relative to business revenue and operating costs vary considerably from one industry vertical to another. For example, in banking and finance, IT expense represents about 6% of revenue and just over 7% of business operating expense; compared to the retail sector, where IT expense represents just under 1.5% of revenue and just over 1.5% of business operating expense.
Cost of platform choice
Businesses have choices on how they will handle their processing needs – and this typically comes down to the mainframe and server farms. The cloud is part of the latter solution. The reality is that any business that runs mainframe systems also runs server farms, so it is fair to characterize them as running “mainframe-heavy” datacenters, while those without mainframe run “server-heavy” datacenters. It is also useful to consider new metrics for these datacenters – MIPS per $1M of revenue and physical servers per $1M of revenue. These aren’t equivalent in any way, but they serve to represent the economics of their computing choices in measurable economic terms.
When comparing businesses within the same industry vertical, the “heaviness” of their IT deployment strategies result in a significant differences. For example, for financial services businesses:
Mainframe-heavy shops consume:
- 3.1 MIPS per $1M of revenue
- 0.22 servers per $1M of revenue
While the server-heavy shops consume:
- 1.75 MIPS per $1M of revenue
- 1.2 servers per $1M of revenue
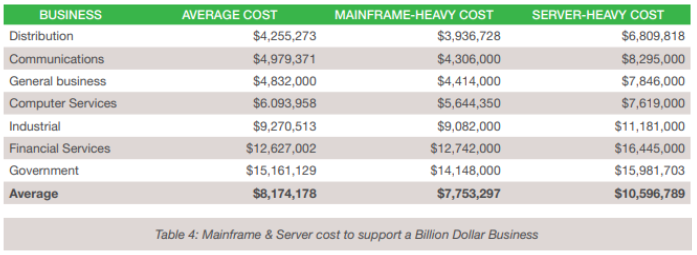
When these figures are mapped to the total cost of mainframe and server farm costs within various industry verticals, the economic differences that can be attributed to their deployment strategies become apparent – see Table 4. The inescapable conclusion is that mainframe-heavy computational costs to support a $1B organization on average may be 30% lower than a server-heavy deployment.
Cost of Goods
While the cost of technology yields interesting conclusions, the actual costs of platform choice are also surprising, and support the former. The next step is to link the technology costs to business costs.
A good way to do that is to use a cost-of-goods metric. Ask the question, “what is the IT cost contribution to the business cost of goods?” And follow that up with, “how does technology deployment affect the measure of impact on the business?” Table 5 itemizes the cost of goods for five business types – finance, industrial, communications, general business and insurance.
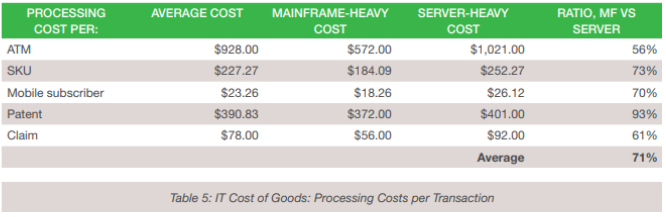
This data implies that where appropriate, effective use of mainframe resources results in a 29% cost advantage over distributed server-heavy deployments.
Looking closely at the insurance data, we see that the average IT cost of processing an insurance claim in a mainframe-heavy environment is approximately $56, which is $36 less than the processing cost in a server-heavy environment. What does that mean to an insurance business? For an insurer that processes 100,000 claims per year, the savings could be $3.6 million per year by leveraging mainframe technology.
Similarly, a bank with 4500 ATMs would be paying over $1000 per ATM using a server-heavy datacenter, as compared to less than $600 using the mainframe-heavy scenario. Such a bank could save more than
$2 million per year by leveraging mainframe technology. Of course, ATM costs are only one small part of a bank’s IT cost concerns.
Competitive advantage
Any large company interested in maximizing computing power AND controlling cost will clearly enjoy a competitive advantage over a similar company that just seeks to avoid mainframe technology in favor of server farms. This advantage translates directly to the bottom line, shareholders and investors. And for a company considering a mainframe migration project as a means for cutting costs, this information could be seen as “found money.”
Conclusions
The facts support the notion that the mainframe is the most powerful and cost-effective computing platform for large businesses with a need for high-intensity transaction processing. Claims to the contrary are typically either as a result of simple lack of knowledge on the subject, or a biased unwillingness to look objectively at the facts.
But if the mainframe is so great, then why is it not being used by the newest and latest concerns (Amazon, eBay, etc.)? The reason is bias. Whether intentional or through ignorance, there is a great deal of bias against the mainframe. It’s too expensive! (It clearly is not.) It’s old and dusty! (Obviously not.) It’s hopelessly outdated! (Not so.) I don’t know very much about it! (Maybe that’s it…)
The last part is the key to the puzzle of why the mainframe generally has a difficult time displacing server farms in environments where it could make a positive impact. The truth is, organizations that could benefit from the mainframe, but don’t, are leaving money on the table.
Where to go from here
So, what about folks who are having trouble keeping up with growing workloads on their “most powerful and cost-effective” mainframes? Should they be upgrading? Shifting workloads off-platform? As you might guess, there are options. There are a couple of organizations that are helping mainframe shops to optimize what they have now – to increase workload throughput of the systems they’re currently running. No upgrade needed; no changes to application logic, no changes to the Db/2 (or whatever) database being used. This is possible using high-performance in-memory technology. And both IBM and DataKinetics are offering these solutions right now.




The reason why newer concerns don’t consider mainframes is that mainframe culture is so crusty and archaic.
While mainframe hardware has kept pace, thanks to POWER, z/OS is still the land that time forgot. And the ops surrounding mainframes are still from the bygone cold-war era when the hardware itself was far more important than the people who tend it.
First, a little about my background: I’m the son of a mainframe’er who spent his entire career (starting with punchcards, ending as a systems programmer for z/vse). I was always the “plastic box” guy, and we’d spend dinner-time conversations when I was a kid debating this. 🙂
The fact that IBM has kept backward compatibility amazes me. An assembled binary program that was written 50 years ago will still generally run on modern systems, despite the underlying silicon COMPLETELY changing. That’s just cool.
Distributed systems are immensely complex, having evolved by solving more and more problems through ever-increasing layers of abstraction. Conversely, the workloads targeted for mainframes are generally simple, and the hardware has scaled with moore’s law. It’s a less-severe example akin to an 1980’s dBase iV database running on a modern threadripper. Same “software stack”, just a way more modern processor.
On the one hand, there’s something to be said for that simplicity. “write once, run anywhere” (java slogan) was the answer to differing *nix processor architectures. IBM solved that problem in hardware in like the 60’s.
That said, “right tool, right job”: Google Search has like 100+ petabytes and does ~63k searches per second against that dataset. Show me a zSeries that can do that. Likewise, show me any distributed system that can reach transaction latencies akin to z/OS on a modern processor. For a given cpu clock cycle, the codepaths are much deeper in the distributed world, and if you need a different node’s help processing the transaction, the additional network hop will destroy the transaction time.
I don’t have nearly as much time to spend on this comment that I’d like, but in general I agree with you, but for slightly different reasons. That said, I do wish IBM made the software running in emulation a bit more accessible. I’ve run z/VSE and z/OS in Hercules, but z/OS was aged. IBM’s licensing is prohibitive (last I knew). They’d do the platform a huge favor is they released downloadable copies of their software for free and allowed it to run in Hercules.
Being the rebel I was, I was “raised” with this anti-mainframe bias. And I don’t t
As an IBM CE I worked on the System 360/370 main frames and associated hardware.
The IBM 360 ran on discrete hardware. Think very large cabinets containing thousands of circuits. Not only that. The I/O was handled by channels. Again think dedicated hardware connecting the CPU to I/O devices but not directly. The CPU would issue CCW’s and the channels would take it from there (another layer was involved but trying to keep it simple). The CPU itself would just keep cranking. There no microprocessor like an Intel 386, just that big CPU cabinet doing calculations and VM like operations. Starting in 2000 or so the mainframe ISA would run on POWER microprocessors but they still had channels and other specialized components. The new Telus chip looks to be very impressive.
I think this is a biased article in favor of mainframes. The overall cost of the mainframe comes up lower because Linux is selected as the OS. I think very very few companies buy mainframes to run just Linux. They buy them to run z/OS and the like, and the software costs for those operating systems are huge.
You are correct, George. I wrote the original article for Mainframe Executive in 2016 that showed a comparison of two platforms running a web server application in Linux. The licensing of software was cheaper for the zLinux platform because of the way it was charged (# of cores). We all know that is not how z/OS workloads are charged. The 2021 article referenced here, misrepresented my work and made claims about all mainframe workloads that were not a part of my study.