



It is well understood that keeping systems and workloads up and running is critical to the success of any organization. Organizations with well-established and tested recovery strategies can restore critical operations rapidly by reducing the impact of both planned outages and unexpected disruptions.
Without such a recovery plan in place, an organization can experience reduced productivity and suffer data loss and irreparable damage to their reputation, resulting in lost customers and revenue.
High Availability and Disaster Recovery
But what exactly are recovery strategies? Terms such as High Availability (HA) and Disaster Recovery (DR) are frequently quoted, but what are these? Fundamentally, High Availability (HA) and Disaster Recovery (DR) are aimed at the same problem – keeping systems and workloads available. The primary difference between the two is that HA is designed to handle issues while systems and workloads are running, whereas DR addresses problems after systems or workloads unexpectedly fail.
HA is about building redundancy directly into the systems and workloads. Systems are tightly clustered, such as in a z/OS Parallel Sysplex®, where the failure of a single system does not impact the availability of the workloads running within the cluster. Multiple instances of the applications making up the workloads are always running, leveraging data sharing environments such as with Db2®, IMS®, or VSAM RLS® – so that the failure or planned maintenance of a single application instance does not affect the availability of the workloads. Redundancy is also achieved at the disk level, using solutions that rapidly swap to a mirrored copy in the event of a disk failure, minimizing impact on systems and workloads.
DR is needed whenever an unexpected outage occurs, such as an environmental disaster or human error, that impacts all workloads and/or systems in an organization’s data center. A different set of systems and disks are present in a recovery data center. The disks in the production data center are replicated to the disks in the recovery data center using appropriate replication solutions. Typically, a recovery data center is geographically distant from the production data center so that a metropolitan disaster does not affect both data centers. Following a failure of the production site, the systems and workloads are restarted using the systems and disks within the recovery site, so that the workloads can be restored to their original states. The effectiveness of any DR solution can be measured by its recovery point objective (RPO) and recovery time objective (RTO). RPO is defined as the maximum amount of data that can be lost after recovering from an unplanned outage. RTO is the maximum amount of time it takes to fully restore the systems and workloads following a failure. Aiming for minimal RPO and RTO is ideal. With asynchronous disk replication, RPO is usually within a few seconds, while restoring systems and workloads in the recovery site can result in an RTO of about one or more hours.
Continuous Availability
So, an organization has a proven recovery plan in place, leveraging a High Availability and Disaster Recovery solution. Is there a need for anything else? Organizations are discovering that although their DR solutions are sufficient for most workloads, there is a subset of workloads that their businesses deem highly critical. There may be significant penalties from a regulatory standpoint, or the potential for large revenue losses, whenever these workloads are not available. Organizations are now being tasked with providing continuous access to these business-critical workloads and their corresponding data, across both planned and unplanned outages. Continuous Availability (CA) is an approach to system and workload design that protects against any downtime, no matter what the cause, and ensures that access to workloads and their data is maintained. While DR focuses on the recovery of all systems and workloads, CA is more precise, focusing on the recovery of specific workloads, without impacting any other workloads running on these systems.
See Figure 1 for how the 3 technologies work.
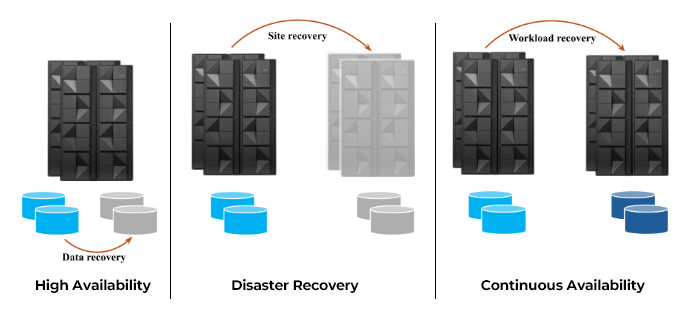
Figure 1: High Availability vs. Disaster Recovery vs. Continuous Availability
GDPS Continuous Availability
The GDPS® Continuous Availability (CA) solution provides this level of workload recovery. GDPS CA defines a workload as the set of applications that comprise the workload, the data sources, such as Db2, IMS, and VSAM RLS, used by the set of applications, and the network access to these applications, such as HTTP requests or MQ messages.
GDPS CA consists of a set of components that provide key features of the solution. Software data replication is used to keep data sources for these critical workloads in sync between the production and recovery sites. The health and availability of the critical workloads and the systems they run on are continuously monitored, so that failures can be immediately reported and acted upon. Workload balancing is enabled across both sites so that applications accessing these critical workloads are transparently routed to the production or recovery site, depending on where the workload is currently active. And a user interface is available that manages the interactions between each of these components and provides a graphical view of the state of the systems and workloads configured to GDPS CA.
Unlike existing DR solutions, GDPS CA relies on the systems and workloads in the recovery site, called the standby site, to be up and running at the same time as the systems and workloads in the production site, called the active site. This ensures an RTO of seconds when recovering a given critical workload. Software replication keeps data sources in sync, ensuring an RPO of seconds following an unplanned outage. This type of configuration, as shown in Figure 2, is called an Active/Standby configuration, meaning that the workload, although available in both sites, is only active in one site at a time, and all requests for that workload are sent to the application instances in the active site. In the event of an unplanned failure of the critical workload, the failure is reported by the monitoring component, and the workload is switched to the standby site, either automatically or manually. For planned outages, such as when applying system maintenance, rather than having to schedule an extended outage for these critical workloads, they can be gracefully switched to the standby site, either one workload at a time or together as a group, while the active site is taken down, using the user interface provided by GDPS CA.
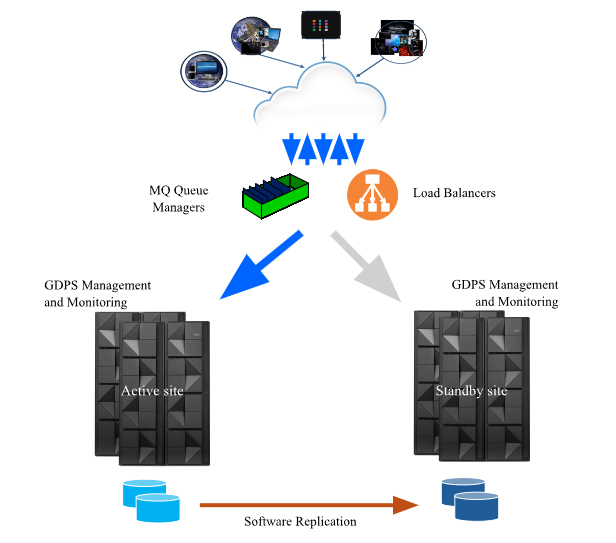
Figure 2: GDPS CA Active/Standby Configuration
A key point to understand is that the GDPS CA solution does not replace an organization’s existing DR solution. GDPS CA is only focused on the business-critical workloads that require rapid recovery times. All other workloads, including batch-type workloads, continue to be recovered using existing DR solutions.
Evaluating Continuous Availability Solutions
Organizations today face increasing pressure to recover quickly from failures of critical workloads, not only to avoid regulatory penalties but also to minimize operational disruptions. At the same time, reducing planned outage windows while managing growing maintenance requirements has become a significant challenge. Additionally, the costs and complexity of maintaining custom-built solutions are becoming increasingly unsustainable. If these challenges are familiar to your organization, it may be worth considering whether a continuous availability solution aligns with your specific needs and objectives. For further details, you can explore the available options and resources.





0 Comments