



The challenge- divergent needs
Viewing IT as a business enabler but also as a major cost center, business leaders demand that IT management find a way to reduce their budget while continuing to deliver excellent performance and availability in an ever more dynamic world. Increasing complexity, higher transaction volumes, and the accelerated growth in both data stores and the need to access this data make it challenging to manage the existing budget, let alone find ways to reduce costs.
At the same time, customers and employees demand even more responsive online applications, while expecting on-demand analytics workload results. The larger the shop, the greater the customer base, and the more difficult it is to find a way to cost-effectively deliver the performance required. As processor speeds continue to increase, data access is the lagging performer. As is often quoted, ‘all processors wait at the same speed.’
Traditional methods for increasing processing performance tend to cost a lot of money and deliver variable results, not the guarantee the IT manager needs. Attempts to exploit memory for performance improvement offer variable results as the kinds of data and varieties of queries – i.e., transactional and analytical – makes it challenging to achieve any substantial ‘wins.’ The mainframe presents a particular problem given the high capital cost of the hardware and even higher costs of the systems software.
Half-measure solutions
There is no silver-bullet solution to this challenge, and any single solution would be a half-measure solution. Here’s why — transactional queries and analytics queries are completely different problems that need to be addressed in completely different ways, especially in large mainframe shops.
For transactional queries, up to 80% of database calls target reference data, data which is frequently read, but much less frequently updated. Calls to large databases usually involve ‘joins’ to these reference tables – these are the ones most responsible for the high overhead and performance impacts on transactional queries. Though many have tried CICS Managed Data Tables (CMDT) or other buffering or in-memory options, the reduction in resource demand hasn’t been sufficient.
For analytics queries, there are completely different things at play. Historically, organizations built completely separate analytics decision support systems. But with the growing need for real-time analytics information, multiple platforms with their inherent data transport delay were clearly not the answer. Unfortunately, running analytics queries directly from the mainframe DB2 database doesn’t work well either, as long-running analytics queries are, by definition, long-running; i.e., they take time to complete. They also consume significant CPU resources on the mainframe, which contributes to the cost of ownership operational expense, and even capital expense costs.
Two separate and unrelated problems are best addressed by two well-targeted solutions.
The solution- two different solutions for two different problems
1. Long-running analytics queries
More data generally means more cost to access and manage it. Thus, tuning activities can provide huge benefits in performance and consistency, ensuring end-user satisfaction regardless of demand fluctuations. Large, complex database queries are the focus for many analysts; these resource-intensive transactions stand out with longer response times and higher resource usage.
IBM’s DB2 Analytics Accelerator (IDAA) has a well-deserved reputation as a solution that provides significant performance increases for large systems running data-intensive and complex analytics queries. Using hardware accelerators, IDAA is designed to optimize complex queries often associated with analytics and other long-running queries.
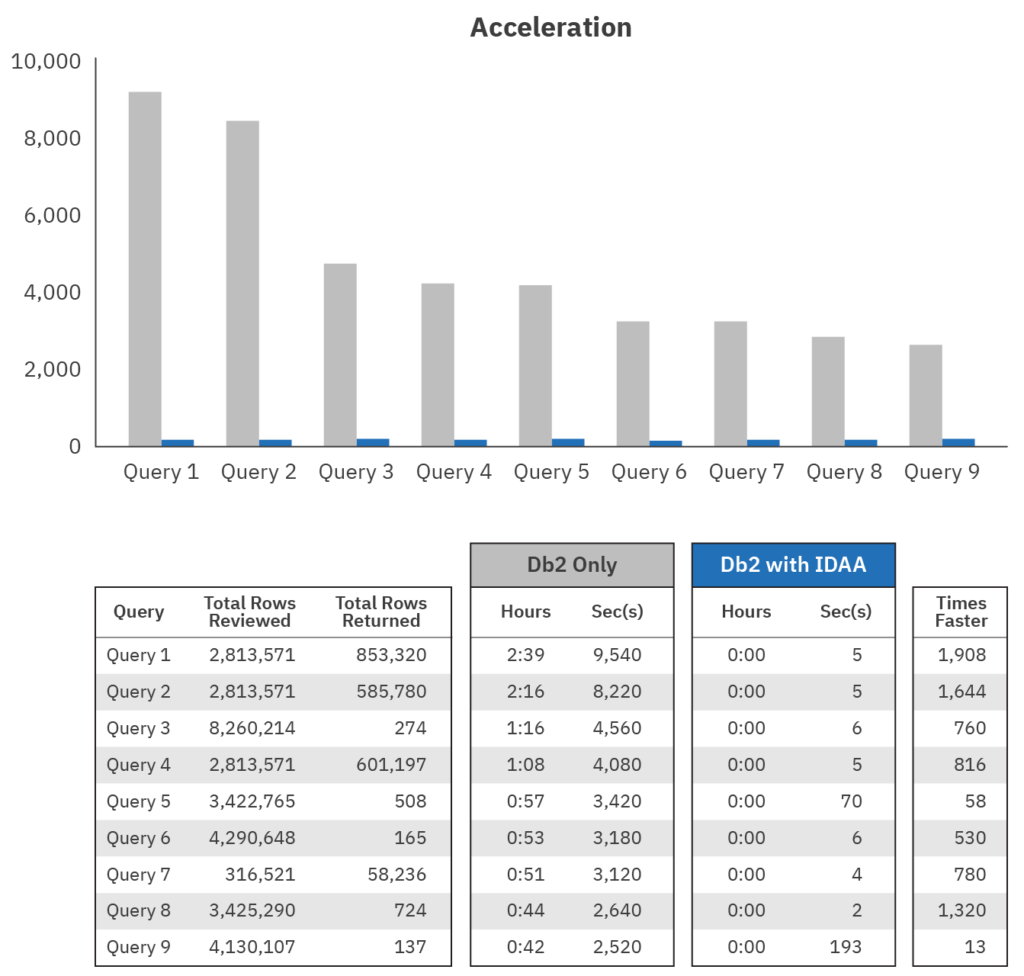
The above image shows IBM’s numbers for expected performance improvements for long-running queries. The numbers are impressive – actual customer performance improvement numbers seem to range from just over 10 up to 100 times faster.
What the numbers do not say is how much faster short transactional queries will run, and that’s because IDAA is not designed to improve performance for those types of transactions. For that, you need a DB2 accelerator.
2. Short transactional queries
Short-running queries are often not considered to be of great concern because each one uses very few resources. However, some of these queries are run very often- sometimes millions, or even billions of times per day. The overall impact of performing many short-running queries many times can have as much impact as performing long-running queries.
Using an in-memory accelerator, with access-optimized in-memory tables to improve access time for short-run queries, is how IBM’s IZTA provides dramatic reductions in resource usage with a patented technique to reduce the access path to data in memory. When implemented for high-volume OLTP or I/O-intensive batch systems, reductions in CPU range from 70-98% are not uncommon, depending on the specific workload. An additional 86-91% CPU reduction was achieved over fully-optimized DB2 buffer pools. The image below shows real customer results—after having done all they could optimizing their DB2 buffering, they were able to gain much more performance using IZTA.
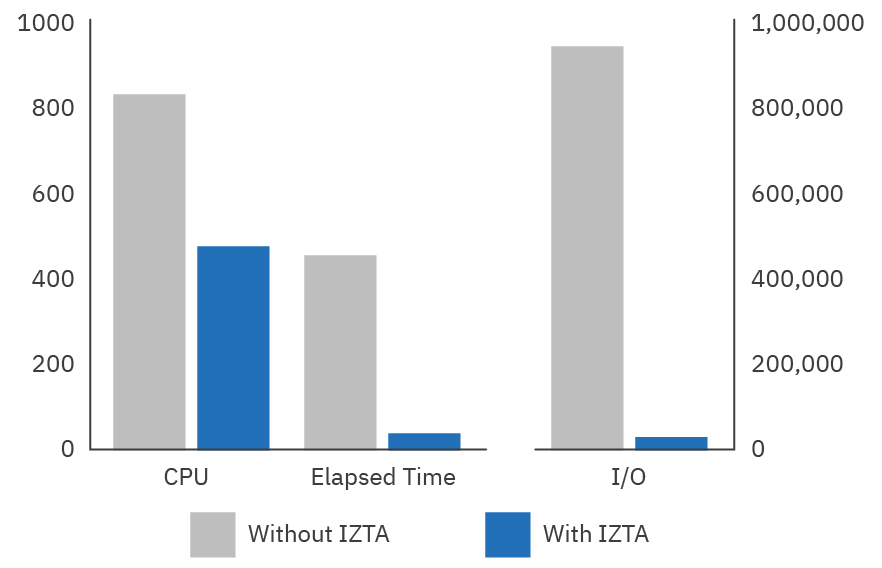
Reduction of CPU use frees up resources for other applications. By reducing the cost of the application, IZTA also helps defer hardware upgrades—and the longer you wait, the less expensive hardware tends to get. Since all major changes to the infrastructure come with increased risk, avoiding these changes increases application availability. In addition, by lowering the cost, the business tends to make a greater per-transaction profit.
IZTA makes this possible by making it possible to relocate the data used most often by an application much closer to the application- and allowing the application to access that data using a very short code path. The image below shows the dramatic difference in code path length.
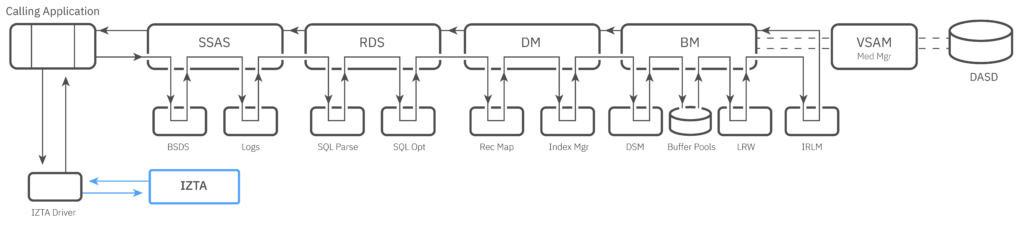
From 5% to 20% of the data accessed by a given application can be copied from the database into access-optimized in-memory tables. This data are then accessed from memory up to 100x faster than otherwise possible using buffering techniques.
IZTA works best for tables less than 2GB in size with an R/W ratio of 100:1 or more. By focusing on long-running and/or CPU-intensive jobs in the SMF type records, then looking for files with high reads per day and high reads relative to row numbers, IBM can help you find the low-hanging fruit for huge CPU savings, which can turn into substantial real dollar savings. In an environment where I/O is $30 per, savings can quickly amount to millions of dollars.
Business benefit
I/O still represents the slowest component of transactional, batch, and analytics work, and it adds significantly to the resource-usage cost of most large enterprises. With IZTA and IDAA, customers can see significant savings quickly, reducing EXCP counts dramatically (much more than can be done using standard buffering techniques). These cost reductions can also, in many cases, result in software cost savings by lowering the R4HA for those who leverage sub-capacity pricing options, depending upon current service agreements.
When resource usage is reduced, there is a corresponding saving on processor and software costs; hardware upgrades can be delayed, which results in a lower mainframe total cost of ownership. By deferring costs, more investment in new technologies and applications is possible. As many companies spend 80% of their IT budget on maintenance, freeing up funds for new development can greatly enhance business competitiveness. Even better, by reducing the slowest component of the system (I/O), performance improvements can be achieved in batch, OLTP, and analytics workloads, which result in increased customer (and employee) satisfaction.
Conclusions
While IDAA adds value by optimizing the more infrequent, but large analytics-based SQL queries, IZTA adds value by optimizing the more frequent, but smaller transaction-based queries. IDAA and IZTA together can help you achieve truly optimized queries allowing you to take full advantage of your hardware spend while delivering on tough service level agreements.
With business leaders demanding reduced IT budgets while maintaining high levels of performance and availability, IT management must have new solutions—for both new long-running analytics queries AND traditional short transactional queries. Two separate and unrelated problems are best addressed by two well-targeted solutions. IDAA and IZTA can provide performance improvements for both long-running and short-running queries, and they can help them to run 100 times faster. This translates into significant reductions in IT operational expenses, combined with an ROI of fewer than 12 months.
If you’re using both IDAA and IZTA, you’re at the forefront of query optimization excellence—in both the transaction processing and analytics processing worlds.




0 Comments