



Introduction
The increasingly hybrid and complex application landscape that spans from distributed to Z is accelerating the challenges that CIOs and IT operations must deal with to maintain the health and resiliency of their hybrid applications and infrastructure. Operations teams are inundated with terabytes of data in real-time that they need to sift through to identify issues before they become an impact, and with limited staff and only 10% having 90% of the critical expertise, you’re dealing with a skills and burnout problem.
Organizations are looking for ways the machine can do more of the heavy lifting which is a major driver for why enterprises are turning to AIOps. The machine can leverage artificial intelligence and machine learning to connect the dots across different data sources and tooling to quickly identify developing problems and surface insights on anomalies and forecasted problems to provide recommendations and automation to remediate the issue, significantly reducing the time to resolution.
Eliminating time to detect and identify problems with AIOps
With AIOps tools doing much of the data collection and processing to detect and identify problems, you are able to significantly reduce the time to diagnose incidents and avoid outages.
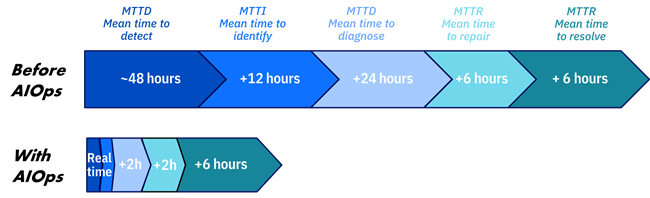
AIOps results in shorter time to diagnose and resolve issues, less effort and skills required, and reduced risk as the identified anomalies detected can help to eliminate impactful outages.
This allows you to get out of REACTIVE mode and start being PROACTIVE by using tools that leverage AI to identify issues or situations that haven’t yet caused a problem but can turn into issues if not resolved. This mitigates the need for bringing everyone together into a war room since the machine has grouped together the key pieces of data and determined the involved/impacted parts of your hybrid application/infrastructure, you can just pull in only the folks needed to quickly resolve the issue.
The complexity of observing hybrid applications
Adopting the hybrid cloud model for enterprise applications provides a number of benefits, but the complexity of monitoring and observing those applications grows exponentially as it may require individual or specialized tooling to monitor each of the components within the hybrid application, generating a lot of events and a lot of noise. AIOps solutions are able to process all of the data and filter down to the most pertinent events that relate to the problem, and in some cases can call out what they believe is the source of the problem.
It’s important to note that AIOps solutions are not a replacement for existing traditional monitoring solutions, they are complimentary and leverage the monitoring results in their analysis. Taken together these monitoring and AIOps solutions can understand the current state of an application and the infrastructure, and perform anomaly detection, event correlation and root cause analysis to improve their hybrid multicloud applications and infrastructure resiliency.
Understanding the impacts of hybrid application issues
Dealing with more than 2000 incidents a month and taking days to detect and diagnose complex issues can result in major outages that can cost over $400k an hour. While outages are costly financially, there is also reputational impact or brand damage to consider too. In banking or retail, a failure of a business critical application can create a negative perception of the brand that can take significant time to recover from.
In our time of social media, bad news can spread fast and competition can be aware of your problems and will react fast to take business away from you. When you think of the size of many IBM Z customers, the numbers can add up quickly with 15% of outages costing more than $5 million per hour.
Where to look next for AIOps
IBM is making significant investments in AI throughout the Z hardware and software stack, as well as building AI-driven solutions, including solutions to enhance the resiliency of Z IT systems. There are many AIOps solutions that bring Z into the AIOps management realm, such as IBM Z Operations Analytics which performs anomaly detection on z/OS and subystems to proactively reduce outages, Db2 AI for z/OS which leverages machine learning to optimize Db2 SQL provide performance tuning recommendation, and IBM Z Performance and Capacity Analytics which leverages machine learning to forecast capacity and for performance profiling of CPU/MIPS usage.
There’s also a capability in the base z/OS that few seem to know about that leverages machine learning called Predictive Failure Analysis. It uses machine learning to determine what’s normal and uses statistical analysis to identify exceptions and anomalies in areas such as common and private storage exhaustion and damages address spaces. Exceptions are alerted and reports are written via the Health Checker for z/OS.
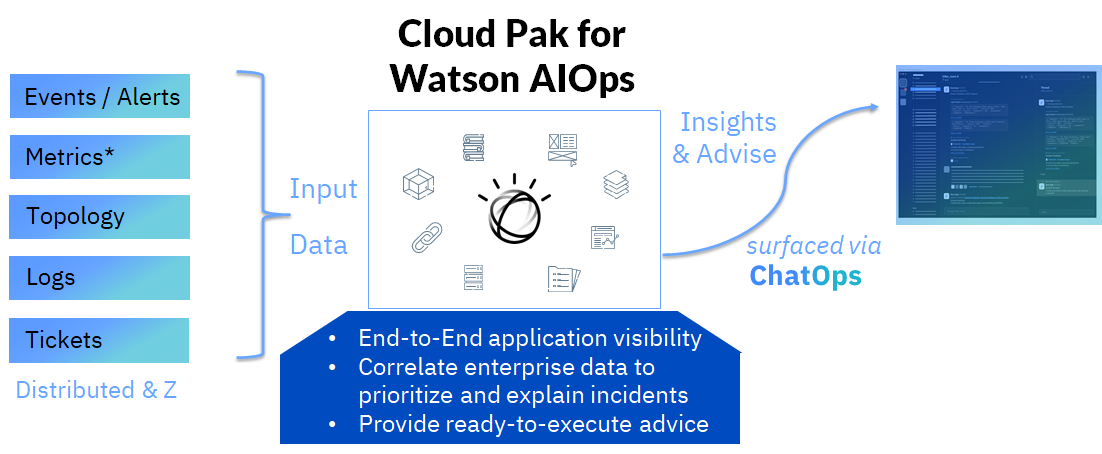
IBM’s flagship solution in the AIOps space, Cloud Pak for Watson AIOps, deserves special mention as it brings together structured and unstructured data sources such as events, metrics, logs, topologies and incidents from across the enterprise. It gives you end-to-end visibility to your hybrid applications to detect and diagnose both application and infrastructure related issues to reduce downtime by allowing your teams to work together on incidents via collaboration tools like Slack and Microsoft Teams. For more information about Cloud Pak for Watson AIOps see the Watson AIOps page.
Depending on where you are on your journey to adopting more AIOps best practices we have developed the following resources:
- To assess your current stage of AIOps maturity and identify action oriented next steps for adopting more AIOps best practices, inquire about the 15-minute online AIOps Assessment for IBM Z.
- Join the AIOps on IBM Z Community to follow this blog series about best practices for taking a hybrid approach to AIOps
- And finally, to research our IBM Z products that are implementing AIOps technologies to improve operational resiliency visit our product portfolio page
Originally published on the IBM Z AIOps Community Blog



0 Comments