



High-quality indexes are critical for fast data access and returns. IBM Db2 for z/OS relies on an advanced data structure called the Optimized Balanced Plus Tree to power high-speed indexing. This structure, an evolution of the classic B+ Tree, helps Db2 deliver predictable, enterprise-scale performance.
In this article, we’ll explain how the Balanced Plus Tree works, why it matters, and how to optimize it for query performance. Indexes are critical for fast data access, and in IBM Db2 for z/OS, the underlying structure powering these indexes is the Optimized Balanced Plus Tree—a refined implementation of the classic B+ Tree tailored for the mainframe environment.
By understanding how a Balanced Plus Tree works, we can:
- Design better indexes
- Tune queries effectively
- Choose the right utilities and options
- Diagnose performance problems at a structural level
Per IBM, the goal of database performance tuning is to minimize the response time of your queries by making the best use of your system resources.
Understanding B+ Trees in Db2 for z/OS
A B+ Tree is a self-balancing, multi-level data structure that maintains sorted order and allows for efficient searches, insertions, deletions, and range scans. Three things are true in a B+ Tree:
- Data (RIDS in Db2) reside in leaf pages
- Internal (non-leaf) pages hold only key values and pointers
- Tree depth is kept minimal for performance
The term “nodes” is common in data structure arenas. Db2 for z/OS refers to them as “pages.”
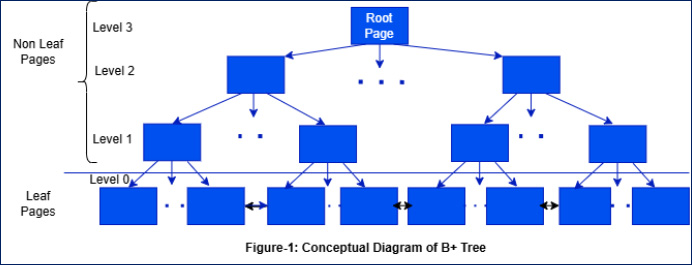
Figure 1 shows that only one Root page, Multiple Intermediate (between Root and Leaf), and Leaf pages are seen. Typical characteristics of the tree are as follows:
- Non-Leaf pages store the key and child page number
- Leaf pages store the key and Pointer (RIDS) to the actual row data
- Tree order ‘d’ defines the number of keys and children in a page
- A 50% minimum occupancy is recommended. For example, a tree order of 4 can have a minimum of two children and max of four.
- Each page can have ‘d’ children or pointers, and ‘d-1’ keys
- The Leaf pages are interlinked forward and backward, facilitating quick range scans.
Db2 Index Optimization Options: Page Splits, Concurrency, and RID Filtering
Db2 for z/OS doesn’t implement a generic B+ Tree. Each one is optimized for I/O efficiency, concurrency, and space reuse. Here’s how:
- Page-Level Optimization
- Db2 uses fixed-size index pages (typically 4K, 8K, 16K, or 32K).
- Page splits and merges are carefully managed to reduce fragmentation and write amplification.
- Dynamic Balance and Minimal Depth
- A balanced tree ensures logarithmic search performance even as data grows.
- The tree adjusts on the fly — with efficient split/merge algorithms — so that access times remain predictable.
- Concurrency and Latching
- Db2 uses latches at the page level rather than locks for structural changes.
- Implement Optimistic Concurrency Control in some cases to reduce contention during index traversal.
- Pseudo-Deletions
- When a row is deleted, Db2 marks the index entry instead of physically removing it immediately.
- Physical cleanup is done later (e.g., during REORG) to avoid costly page reorganizations during normal operations.
- RID Mapping and Filtering
- Leaf pages store Record IDs (RIDs), which point to rows in the base table.
- Efficient RID list building supports Index ANDing and hybrid access paths like index-only scans, index screening, or multi-index access.
Typical Operations on B+ Tree: Search, Insert, and Delete
1. Search Operation: Equality and Range Predicates
For a search operation, start from the Root page as shown in Figure 2. Examine index entries in a non-leaf finding Child page. Go down the tree until a leaf page is reached. Keep in mind that non-leaf pages can be searched using a binary or a linear search. For Range, once you search hit target key, then do sequential traversal in leaf pages.
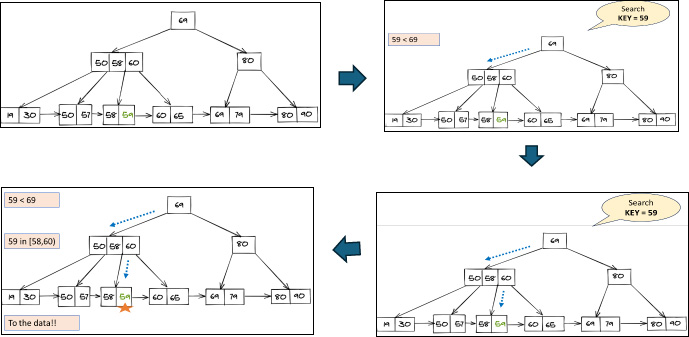
Figure 2: Search Operation
2. Insert Operation
Search in the B+ tree to check the page where this new key should go.
If the page is not full, add a new element to it. Use the same flow as for Search.
If the page is full:
- Split the page into two (acquire a new page) as shown in Figure 3.
- Push the middle/median element to the parent.
- Insert the new element.
- Repeat the above steps if the Parent exists.
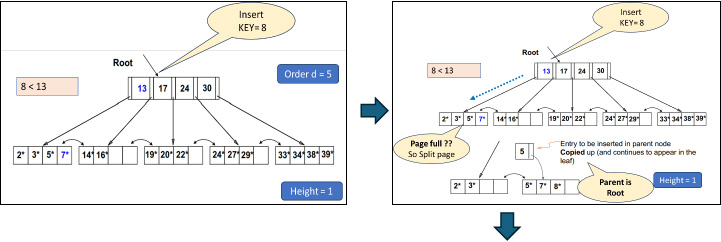
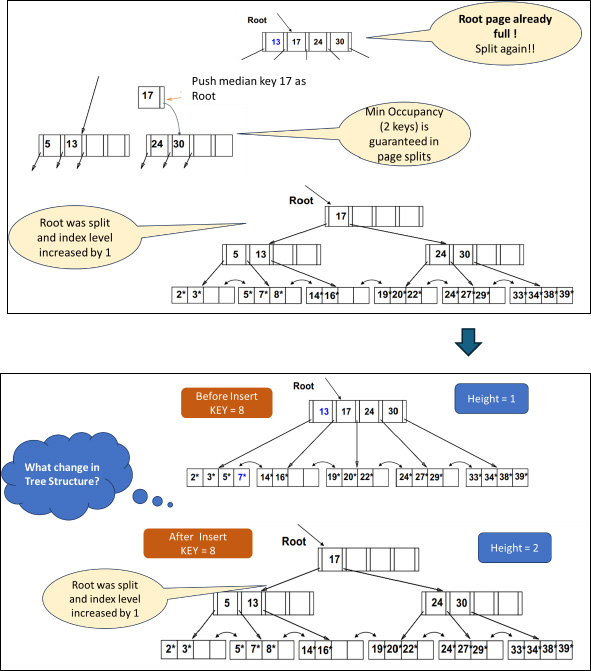
Figure 3: Page Split during Insert Operation
3. Delete Operation
- Search and descend to the leaf where the key exists.
- Remove the required key and the associated reference from the node.
- Note that in Db2 for z/OS, it is pseudo delete, and just marked as deleted.
Db2 for z/OS Index
The Index Page set up in Figure 4 includes:
- Header Page: Control information used by DB2.
- Space map Page — outlines the space available for a range of pages.
- Directory Page — for Versioning information
The Root Page, Non-Leaf Page, and Leaf Page all fall under Data pages.
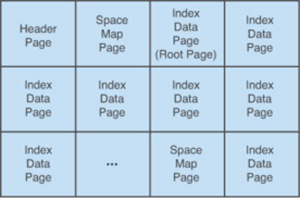
Figure 4: Index space Layout
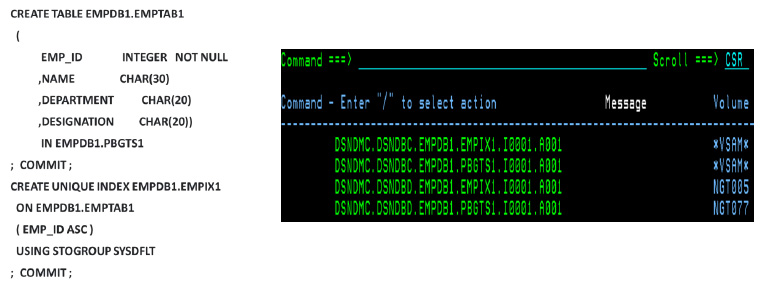
Figure 5: Example of CREATE TABLE and CREATE INDEX statement.
Header Page
Layout the Header page as shown in Figure 6. Control information like OBID, DBID, RBA/LRSN, SS name, CAT name, Part number, Page size, Page numbers, etc.
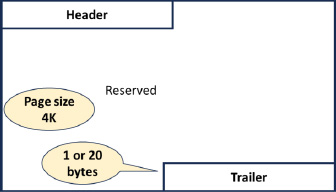
Figure 6: Index Header Page
Space Map Page
The space map page contains Pages free and occupied. Use a 4-bit map per page as in Figure 7. The range of pages mapped in one space map page is
PAGESIZE-LENGTH(PGTAIL)-HDR LEN.
For a 4K page, it can map 8132 pages [ (4096-2-28)×2 ].
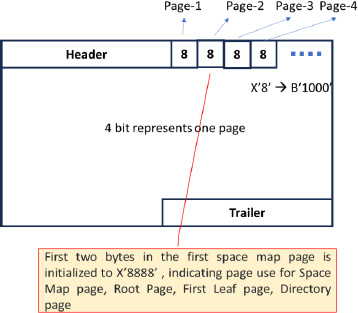
Figure 7: Space Map Page
Non-leaf Page
Each non-leaf page contains high keys with child page pointers, as shown in Figure 8. However, the last page has no High Key because it points to a child page with entries greater than the highest key in the parent.

Figure 8: Non-leaf Page
Leaf Page
Figure 9 shows the map of a Leaf page that contains the index entries for the keys, the RIDS, which are pointers to the table rows.
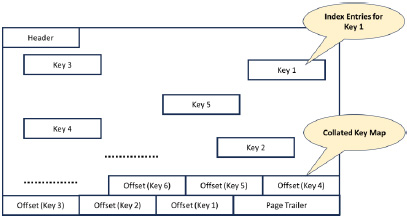
Figure 9: Leaf Page
Index Entries
The structure of index entries is shown in Figure 10. A chain of RIDs is appended to the end of a contiguous RID. When there is no room to insert, create a RID chain. RIDS contain the part number, page number and Map Id entry information.
Note that the term ‘Flag’ indicates pseudo-delete, possibly coming from uncommitted rows.
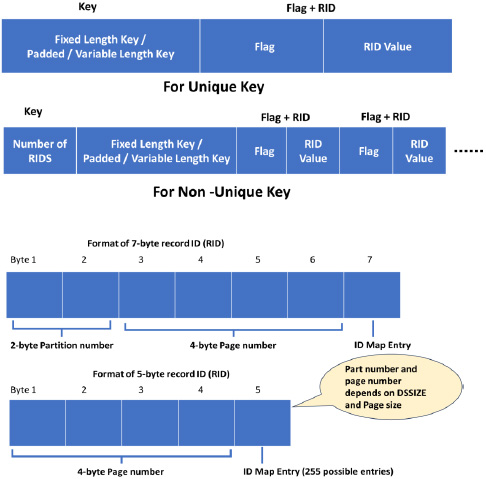
Figure 10: Structure of Index entries and RIDS
Factors affecting Db2 Index Performance
The first factor may be scattered or fragmented pages. Scattered pages occur when related data is stored in non-contiguous locations within the database. This can happen with frequent Update/Insert/Delete.
The other factor that may slow performance is the number of levels in the index structure. The depth/height of an index tree refers to the number of levels in the index structure. Typically, levels increase because of data growth, uneven data distribution, insert/delete, and index fragmentation.
Shallower indexes require fewer I/O operations to traverse the index structure.
Timely and periodic REORG helps defragment the index, reestablish physical locality, and maintain shallow index structures — all of which are key to ensuring optimal performance.
For example, with a B+ Tree fan-out of 100, the tree depth is:
- Level 0 (leaves): 100,000 pages
- Level 1 (pointers): 1,000 pages
- Level 2 (root): 1 page
This means any search would require at most 3 I/O’s — and often less due to buffer pool caching. That’s the power of logarithmic performance!
Optimized B+ Tree – A Masterpiece of Mainframe Engineering
The Optimized B+ Tree for the index structure in Db2 for z/OS is a masterpiece of mainframe engineering that balances performance, concurrency, and manageability. It’s the silent workhorse behind nearly every index scan, join, and access path decision.
Learn more about Db2 indexing strategies and what’s new in Db2 on Planet Mainframe.




0 Comments