


Last week we ended with Db2 Performance of zHyperLink Read.
Now let’s look at the CPU cost of zHyperLink read.
As explained last week, I/O operation is now synchronous to CPU with zHyperLink and SQL processing spins while waiting for the I/O to complete. At the same time, with zHyperLink, there is no longer suspend/resume operation, z/OS dispatching wait, or I/O interrupt processing.
The CPU impact of zHyperLinks depends on multiple factors as indicated in Figure 6. While latency benefit is same, zHyperLink cost depends on:
The speed of processors – The faster the processors, it spins faster, thus waiting I/O becomes more expensive.
The path reduction and processor cache benefit – Path length saving from avoiding the I/O interrupt and dispatching operations as well as avoiding missing the processor cache during I/O operation. While the path length saving is consistent, the benefit from cache miss depends on Relative nesting intensity (RNI) of your workloads (see reference below for RNI)
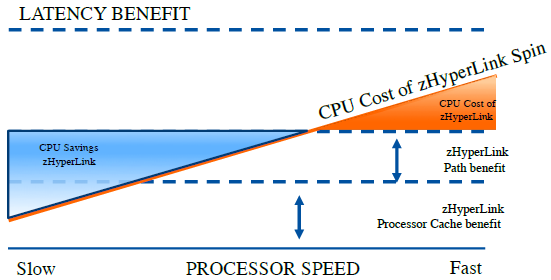
Figure 6. CPU impact from zHyperLink Read
Figure 7 shows the CPU time impact of using zHyperLink read using the same measurements in Figure 3 and 4 on the full speed z14 LPAR with 10 CPs.
With 70 GB buffer pools, we observed 5% CPU increase in LPAR level, and 13.8% CPU increase with 10GB buffer pool size. The majority of the cost is in Db2 class 2 time. Since there were less zHyperLink I/Os with 70GB buffer pools compared to 10GB buffer pools, we observed less elapsed time benefit, and also less CPU impact.
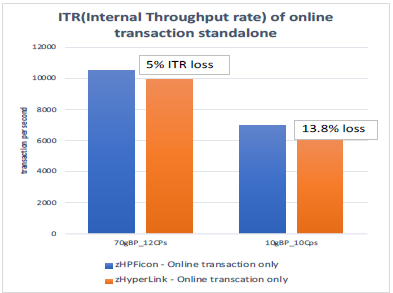
Figure 7. Internal Throughput Rate : online transaction only
The above measurements were done on the LPAR where we only execute Db2 transaction workload. While the measurements in Figure 7 are clean, Lab-controlled results, the measurements showing in the Figure 8 are likely more realistic and simulate real world Db2 application usage better. In Figure 8 measurements, we executed the background Db2 applications such as Db2 batch queries in addition to the online transactions.
With the background workload running, we saw significantly smaller overhead (1 to 3.4% CPU impact) with zHyperLink enabled. This is likely due to more disruptions in the processor cache with the background workloads and the cost of standard I/Os get more expensive than pristine environment.
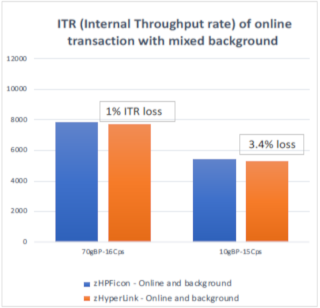
Figure 8. Internal Throughput Rate : online transaction and background work
The processor speeds also influence the CPU impact of zHyperLinks. The measurements reported in Figure 9 are taken with z14 Model ZR1 processors with lower CPU cycle speed using the similar workloads but using less transaction rate since the processor speed is significantly reduced compared to full speed z14. Interestingly, as we lower the processor speed from ZR1 Z06 to ZR1 I06, the CPU impact of zHyperLink shifts from negative to positive. This demonstrates well on the point of figure 5 where CPU saving and cost crosses at some point and cost “depends” on many factors.

Figure 9. ZR1 measurements
Db2 Active Log Writes via zHyperLinks
zHyperLink write support became available in December 2018. Just like read, the write support is limited to 4K CI data set. zHyperLink write technology supports Metro Mirror and HyperSwap within 150 meter distances. However, Asynchronous replication (Global Mirror, zGlobal Mirror (XRC), Global Copy), Safeguarded Copy, and DS8882F are not supported for zHyperLink write operations at the time of writing. Another notable restriction is that write I/O is limited within 2 tracks. For the write I/O requests greater than 2 tracks, z/OS will create multiple I/Os on behalf of requesters.
Db2 12 for z/OS exploits zHyperLink write capability for active log write. Db2 active logs are typically defined with CI size 4K. When Db2 application issues updates, Db2 log needs to be materialized at the commit. The transaction waits until the commit completes and log writes can become significant in update, insert intensive Db2 applications. In data sharing environment, when an index page set becomes GBP dependent, Db2 needs to force the log write during the index split. This is done while holding Db2 latch to maintain data integrity across the data sharing group and often becomes the noticeable bottleneck in heavy insert applications.
zHyperLink write can help to improve the transaction latency and other additional contention by reducing the log write wait time significantly. zHyperLink write for Db2 active log can be enabled through specifying the system parameter ZHYPERLINK ACTIVELOG or ENABLE. Just as zHyperLink read, the SMS storage class of the Db2 active log data sets must be enabled for zHyperLink write eligibility using the Integrated Storage Management Facility (ISMF).
If metro mirror (PPRC) is enabled for the active log data sets, zHyperLink uses zHyperWrite technology to write to the secondary. When you enable ZHYPERLINK write, z/OS will enable zHyperWrite for peer write regardless what you specify with zHyperWrite system parameter (REMOTE_COPY_SW_ACCEL ) provided the distance between primary and secondary is within 150 meters.
Performance of zHyperLink Write
To demonstrate the benefit of zHyperLink write support, the measurement is done with 100 threads inserting into a table with 3 indexes with Member Cluster YES using insert algorithm 2 in 2 way data sharing environment. Due to significant reduction from log write wait time during commit and index splits, zHyperLink shows up to 40% throughput increase compared to using the High performance Ficon.
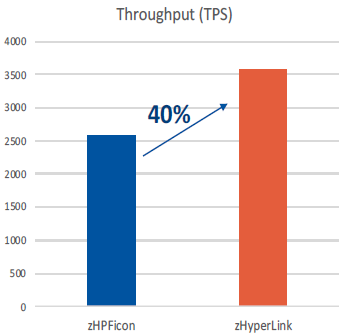
Figure 10. Throughput Rate : insert transaction per second with zHyperLink
Figure 11. CPU per transaction with zHyperLink Write
In terms of CPU time, Db2 log write I/Os are done under Db2 MSTR address space and zIIP eligible. There was no CPU impact to the application (class 1 and class 2) since CPU increase from using zHyperLink is measured under MSTR address space in statistics and it is 100% zIIP eligible time.
Monitoring zHyperLink Usage
Several instrumentations are added to Db2 for z/OS to monitor zHyperLink usage in Db2. An accounting trace reports the number of zHyperLink read I/Os (QBACSYI) and CPU usage for read (QBACSYIT). Statistics trace includes the number of successful reads using zHyperLinks (QBSTSYIO), the number of read I/Os which hit the disk cache but not using zHyperLinks (QBSTSIOC) and the number of zHyperLink Log write I/O requests (QJSTSYCW). IFCID 199 and display buffer pool commands have also been enhanced to report zHyperLink activities.
Will your Workloads benefit from zHyperLink technology?
To understand the possible benefit from the zHyperLink, you can utilize SMF 42 type 6 data set level statistics from your workloads and IBM Z Batch Network Analyzer (zBNA) Tool.
Conclusions
To summarize, zHyperLink is an innovative mainframe link technology and can be used to reduce Db2 transaction latency. IBM’s control measurements show up to 50% elapsed time reductions for Db2 transactions. There are several considerations that you should be aware such as hardware restrictions, eligibility and possible CPU impact as described above. If the restrictions are acceptable, we recommend to utilize zBNA tool to estimate the possible benefit before setting up zHyperLinks.
I hope the article is helpful to understand Db2 exploitation of zHyperLinks technology. Thanks for reading!
I would like to add a special thanks to Neena Cherian, Db2 performance, IBM for her contributions on all of the detail performance measurements and analysis covered in this article.
References :
IBM Redbook : Getting Started with IBM zHyperLink for z/OS
Relative Nest Intensity from IBM LSPR
This article was recently published on the IDUG website.
Akiko Hoshikawa is a Senior Technical Staff Member with the IBM Silicon Valley Lab, where she leads the performance engineers for Db2 for z/OS development. She is responsible of driving performance initiated development in each Db2 releases working closely with Db2 developers. She has been working in the Db2 for z/OS performance team since 1997, executing performance evaluations of new Db2 releases and supporting numerous customers performance tuning and vendor benchmarks.