


Parallel Sysplex – a type of Clustering Technique
Parallel Sysplex on the IBM Z Mainframes is nothing but a type of clustering technique. Almost all mainframe installations (except, maybe, the smallest installations) typically use clustering techniques.
There can be simple clustering techniques such as a basic shared DASD configuration where the Operations personnel would control which jobs go to which system and ensures that conflicts in the form of multiple systems trying to update the same data set at the same time do not occur.
And, on the other side of these simple clustering techniques are some real sophisticated ones. A Parallel Sysplex is one of the most sophisticated of all clustering techniques.
Let us first look at what a Sysplex is
IBM defines a Sysplex to be a “a collection of z/OS systems that cooperate, using certain hardware and software products, to process work“. Thus, a Sysplex can be considered a clustering technology.
Benefits that a Sysplex provides: –
- Near-continuous system availability
- When compared to a stand-alone system, a Sysplex means that you now have a greater number of processing units and z/OS operating systems that cooperate among themselves. Thus, a Sysplex delivers an improved growth potential.
- The ‘improved growth potential’ that a Sysplex delivers eventually helps in increasing the amount of work that can be processed.
Now that we have understood what a Sysplex is and the benefits that it delivers to your Mainframe shop, let’s concentrate again on “Parallel” Sysplex
A “Parallel” Sysplex is a ‘Sysplex’ that uses multi-system data sharing technology. Using the Parallel Sysplex clustering technology, you can link up to 32 servers to create an extremely powerful commercial processing clustered system. In a parallel Sysplex processing clustered system, you can link servers with ‘near linear’ scalability.
In a parallel Sysplex processing clustered system, every server has access to all data resources. Moreover, it is possible for every cloned application to
run on every available server. What does that mean? Work requests such as business transactions or database queries that are associated with a single workload, can be dynamically distributed for parallel execution (and hence the name “Parallel Sysplex”) on nodes in the Sysplex cluster based on available processor capacity.
The figure below shows a specific type of configuration within a Parallel Sysplex, where multiple mainframe servers have been clustered together. Do remember that the figure displays only a specific type of configuration; there can be many different types of configurations within a parallel Sysplex environment.
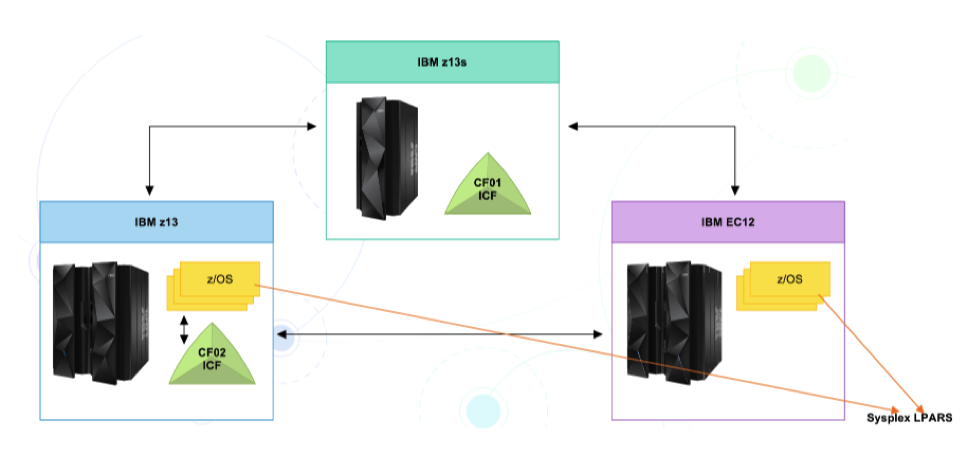
Figure. One of the many types of Parallel Sysplex configurations
The figure above depicts a specific type of Parallel Sysplex configuration wherein multiple mainframe servers have been clustered together to form a Parallel Sysplex environment. In the above scenario, two IBM z13 mainframe servers and an older IBM EC12 mainframe server are connected. The IBM z13 mainframe servers contain Coupling Facilities (CFs).
- Advantages of a Parallel Sysplex configuration: –
- Availability: Parallel Sysplex design characteristics help businesses run continuously
- With Parallel Sysplex design characteristics, it is possible for sites to dynamically add and change systems in the Sysplex. It is thus possible to configure the systems for no single points of failure.
- Parallel Sysplex is a state-of-the-art clustering technology using which the mainframe sites can make multiple z/OS systems work cooperatively, that in turn results in processing the largest commercial workloads more efficiently.
- Parallel Sysplex configuration allows systems in a cluster share processing and resources
And, it is now the time for us to peek into the world of “Coupling Facilities (CFs)”
As we saw in the figure above, a Parallel Sysplex relies on one or more Coupling Facilities (CFs). A coupling facility is a mainframe processor with
- memory – a coupling facility typically has a large memory
- a very small built-in operating system
- special channels – other than the special channels, a coupling facility has no I/O devices.
We have already read above how a Parallel Sysplex clustering technique is able to provide a “shared data” technology through which all the systems that are part of the Sysplex engage in ‘multi-system data sharing’. How is this ‘multi-system data sharing’ possible? Let us think about this – while the idea of a ‘multi-system data sharing’ technology sounds cool, a lot of work must be done to ensure Performance and Data Integrity. Guess what? A Coupling Facility (CF) mainframe processor has been designed to ensure just that – to ensure a high performance read/write integrity with ‘multi-system data sharing’ happening on a Parallel Sysplex clustering configuration.
When used with the Coupling Facility (CF) technology, a Parallel Sysplex clustering configuration/design allows direct, concurrent read/write access to shared data from all the processing nodes (or servers) present in the Sysplex configuration without impacting performance or data integrity. In short, coupling facilities (CFs) are used to facilitate the sharing and movement of data between logical partitions (LPARs) within the connected Sysplex network.
A Coupling Facility (CF) largely functions as a fast scratch pad and is essentially used for three primary purposes.
- Locking information,
- Cache information (such as for a database),
- Data list information,
that are all shared among all the systems attached/connected to the Sysplex network.
Subhasish Sarkar is a Senior SQA Engineer, working at BMC Software India Pvt Ltd. He has 12+ years of relevant work experience in different IBM Z Mainframe Technologies. He is passionate and enthusiastic about Technology in general, the IBM Z Mainframe Platform in particular and IMS to be specific. Subhasish Sarkar is an IBM Z Champion (for 2020).
Follow on Twitter
Connect on LinkedIn